Scotland's Census 2022 - Census–Census Linking and Overcount Correction – Final Methodology
Background
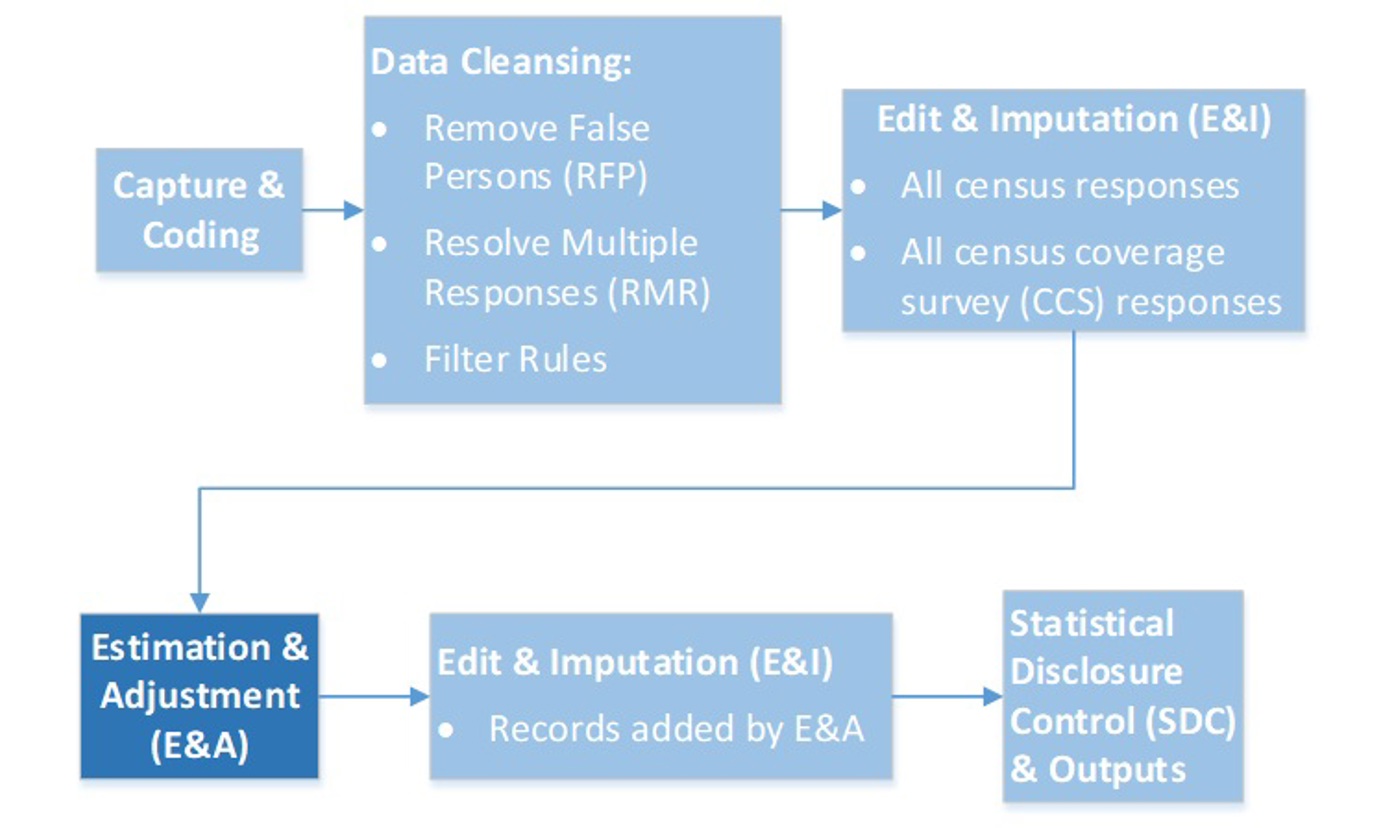
Estimation is the process where the data collected in the census is adjusted to cover 100 per cent of the population of Scotland (see Figure 1). In producing population estimates from the Census, undercount is the primary issue, where households do not complete a questionnaire. However, there are cases of overcount in Census returns, where there are extra records, which should not have been included.
There are four types of overcount:
· Type 1 — Duplication of individuals within the same location
o These are duplicates where a person has either been included multiple times in the same household return, or in two or more separate returns for the same household.
· Type 2 — Individuals enumerated in more than one location
o These are duplicates where a person has been included in more than one household return at different addresses, such as a child with separated parents included in the household of each parent.
· Type 3 — Individuals enumerated in the wrong location
o These are cases where a person has been missed in the household where they should have been enumerated, but included in a household where they should not have been enumerated. This results in undercount in the area where they were missed, and overcount in the area where they were included.
· Type 4 — Erroneous returns
o These can be returns which are fictitious or joke returns, as well as cases of babies that were born after Census day or individuals who died before Census day and as such should not have been included.
o These are difficult to identify without additional field work or linking to vital events data.
If overcount is not identified and accounted for then this can lead overestimating the population. Type 1 overcount will be identified and resolved in the Resolve Multiple Responses (RMR) process as part of Data Cleansing. The Remove False Persons process will deal with Type 4 overcount, to the extent that this is possible. This paper therefore covers methodology for dealing with types 2 and 3 overcount.
To identify Type 2 overcount, this paper presents the method to link the census to itself, with the linked records then being linked to an administrative dataset. For each census–census link the number where one or both of the census records link to the administrative dataset is identified. Using this, the probability of each census record representing a distinct genuine individual is calculated.
To identify Type 3 overcount, the Census–CCS links were used to identify people who were enumerated in different locations between the Census and CCS.
This paper presents how the numbers of records identified as overcount can be used to correct the population estimates.
This paper is an update to the original PMP015: Census to Census Linking and Overcount Correction External Methodology Assurance Panel (EMAPs) paper, which was published before data processing started.
2022 Method
2.1 Census – Census Linking
All households in Scotland are required to complete a census return for all usually resident persons. Respondents should be recorded at their place of usual residence, and so should appear on the census exactly once. However, some people may have more than one residence and so they may appear on the census at more than one location. A common example is that of children who live part of the time with each of their separated parents. If not accounted for, these effects will result in an overestimate in the population.
To account for such cases the census dataset is linked to itself. Links found between records in different locations are then considered (links between records at the same location are dealt with in the Resolve Multiple Returns (RMR) process). Unlike in the RMR process, the records in these links cannot be resolved. One reason is that it would be difficult to know at which location the individual should be recorded.
Therefore, in order to account for this overcoverage, probabilities will be calculated for each census record, indicating the likelihood that the record represents a genuine distinct individual. To find this, the records in the census links are linked to an administrative dataset. Using the number of links where both census records, one of the census records, or neither of the census records link to the administrative dataset, probabilities that each link represents one or two individuals can be calculated. This in turn can be used to calculate the probability that each record represents a genuine distinct individual, which is then attached to the record. By considering the difference between the total number of census records, and the sum of the probabilities attached to them, the scale of overcoverage can be estimated. For example, if two records are believed to represent the same person, they can both be given a value of 0.5, so that summing these adds one to the total estimated number of people in the population.
2.2 Changes made to the methodology during processing
Quality assurance of the running of this process on the live census data revealed that in a small number of cases census records linked to more than one other census record. The calculations that are applied assume that each link involves records that do not appear in any other links. The fact that this assumption does not always hold caused problems both for the calculation of the probabilities to be applied, and also in how these probabilities were applied to the records involved in these multiple cases.
To address this issue the records involved in such cases were excluded from the calculation of the probabilities for the corresponding stratum. This removes the links in the whole group. So if record A linked to B and B linked to C, then all records A, B and C (along with the links involving those records) would be excluded. This resulted in a cleaner calculation for the probabilities, resolving the first problem.
Applying the probabilities was done differently for cases with more than two records linked together. It remained the case that census records that link to an administrative data record would still be given a probability of 1, as the presence of an the administrative data record is taken as evidence that the record represents a person at that location.
Note that in some of these groups there could be multiple census records in the same postcode, and hence link to the same administrative data record. For example if A links to B and B to C then A and C could be at the same postcode and both link to the same administrative data record. A and C would not be linked directly as the process does not consider links between records in the same postcode, as these will already have been considered by the RMR processing step. As such records have been considered by RMR and not resolved, it is required that such cases remain as RMR left them, so it is correct that both A and C get assigned a probability of 1.
For the remaining records we would not want to give them the same probability as normal. For example, consider the case where three census records all link very strongly to each other, but none link to administrative data. If there were just two then each would get a probability around 0.5, indicating that we think the records between them likely represent one individual, but we have no evidence to suggest which location is correct. If we assigned 0.5 to each of the three census records, then we would end up with a total across the three of 1.5, even though it is likely that there is only one person represented across the three records.
To address this the total of the probabilities normally assigned across records not linking to administrative data are shared evenly among all such records in the group. So in the above example we would normally assign 2 x 0.5 = 1 across the records, so we now share that among the three records, giving each a probability of 0.33. In this way the total of the probabilities across the group when neither or one of the records link to administrative data, will match the total in cases where there are two records in the group (and neither or one of them link to administrative data).
Conclusion
The methodology for Census–Census Linking and Overcount Correction was used successfully, and the use of administrative data improved the quality of the data. 0.6 per cent of census records were given a probability less than 1. The total of the probabilities over all the census records was 0.5 per cent lower than the number of census records. These probabilities were then used in estimation to reduce the final estimates accordingly.
A change was applied to appropriately handle the small number of cases that did not fit the usual pattern with one census record linking to exactly one other census record.