Scotland's Census 2022 - Resolving Multiple Responses: Identify Duplicates – Final Methodology
1. Background
Resolve Multiple Responses (RMR) is the third data cleansing step in the census data processing journey.
There are situations when people submit more than one response to the Census. This is sometimes for legitimate reasons; if a respondent is making a paper response but the household is larger than five people, for example, they are asked to submit another questionnaire (a continuation form). These situations do not result in overcount and pose no problems in terms of accuracy and data quality. However, there are also situations where someone responds to the Census more than once and it causes issues in data quality — where people, or even whole households, are duplicated in the dataset. This can occur for a number of reasons, for example:
- Where someone in the household fills out the questionnaire and sends it off, but someone else in the household has already done this;
- When someone changes their mind about what they want to include in their response, and submits a new one;
- A respondent begins filling in the census return online but decides they would rather fill it in on paper. In such cases the information on the online return would be collected as an unsubmitted return;
- A respondent begins filling in the census return online, but forgets their login details before completing it. They would then need to request a new Internet Access Code (IAC) and begin a new return. Again, the information on the first return would be collected as an unsubmitted return;
- Where a person gets confused about a paper response, and answers the individual questions for themselves for Persons 1–5 (each paper household questionnaire contains spaces for up to five people)
This duplication creates what is called ‘overcount’, an inflation in the count of people or households. Overcount can lead to an overestimation of the population. Therefore, the process that looks at duplication of individuals at a location — Resolve Multiple Responses (RMR) — is an important part of data cleansing. This identifies multiple person census records that are believed to all represent the same individual, and resolve them together so that individuals appearing in the census dataset appear exactly once.
The first step in RMR is to identify those responses that may be duplicates of this nature. The approach for Scotland’s Census in 2022 resolved cases where this occurred within the same household, and within the same postcode. RMR’s purpose is to deal with duplication within households. However, it is possible that individuals from the same household could have their address recorded differently, if they edit their address on their return. In order to identify such cases RMR was carried out at postcode, rather than household level. Cases where a person appears at genuinely different locations cannot be dealt with using RMR, as it would not be known where the person should appear. Therefore, duplicates across postcodes were dealt with using a separate process called Census to Census linking, which is described in Census–Census Linking and Overcount Correction – Final Methodology.
This paper covers the methodology used in the linking/identifying aspect of Resolve Multiple Responses. That is identifying which individuals or households appear more than once. The methodology for resolving the duplicate records, is published in a separate paper: Resolve Multiple Responses: Resolving Duplicates – Final Methodology.
This paper is an update to the original RMR Identify Duplicates External Methodology Assurance Panel (EMAPs) paper, which was published before data processing started. More information on the detailed background and methodology of the process can be found here: PMP014: Resolve multiple responses - identify duplicates | Scotland's Census (scotlandscensus.gov.uk)
2. 2022 Method
2.1 Census – Census Linking
This method links the census to itself using comparisons of the key variables: date of birth, name (first name, last name and middle name) and sex. The linking method only considers pairs of records in the same postcode. For each pair, a score is assigned for each linking variable, depending on how similar (accounting for differences such as typos, character level check, phonetic similarity) the records are on these linking fields. Then this is converted into evidence for and against the records being a match (that is, the two records representing the same individual). The scoring is done in the same way as for other census linking tasks and was developed to reflect the judgements of a human reviewer. Having separate scores for evidence for and evidence against a match allows cases where information is slightly different to be distinguished from cases where information is missing. Pairs where much of the information used for linking is missing would sit at the lower left of Figure 2, while those with conflicting evidence would appear at the upper right.
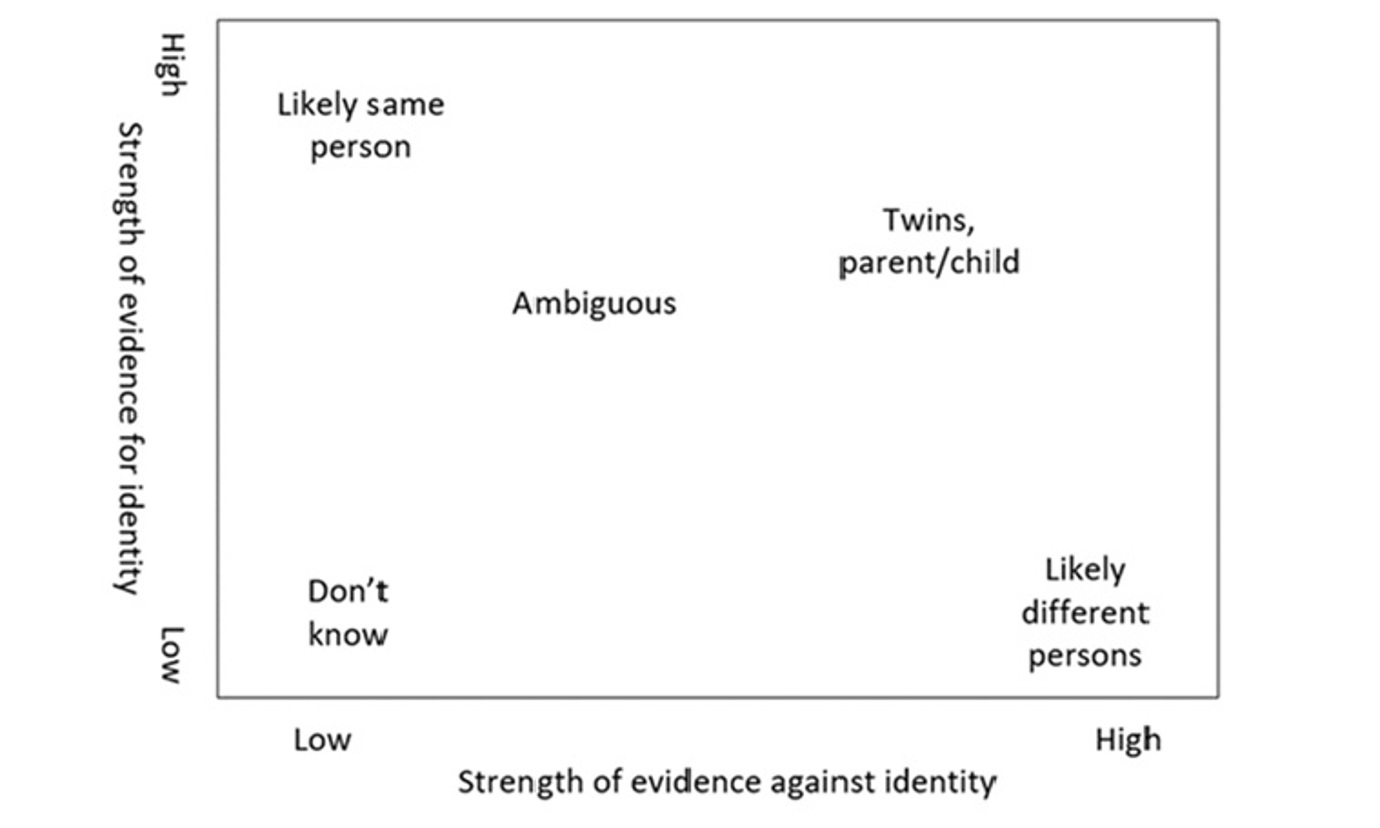
The links are then categorised by the strength of their evidence for and against for the different variables. These categories include possible Parent/Child pairs or Twins. For example John Smith born 1960 and John Smith born 1991 living at the same location would be considered a parent and child pair. 78 categories of links were developed. If the records are from the same questionnaire then there may be information on the relationship between the persons represented by the two records, for example that one is the parent of the other. If this information is present then it provides further evidence that the records represent distinct individuals, and so is considered when categorising the link.
A sample of the cases in each category was reviewed, and on the basis of this the categories were then classed into:
1. Automatically flagged for resolution
2. Passed for clerical review, or
3. Automatically discarded (records linked with these links were not resolved)
Categories were placed in the automatic resolution set if the links were generally considered matches, in the automatic discarded set if the links were generally considered non-matches, and in the group for clerical review if there were a mixture or it was felt that some could be ambiguous.
Having so many categories allows decisions on whether or not to resolve a link, to be applied to all similar links. This then reduces the number of categories where the links need to be clerically reviewed. Even for categories where the links are passed to clerical review, if, during review, it is found that all the links are accepted, or all rejected, this can then be applied to all further links in that category.
Records are then assigned to a group so that all the records in a group link to each other directly or indirectly. Indirect links are when records do not link directly to each other, but do link via another record. (For example, if A links to B, and B to C, then A links indirectly to C.) Groups of linked census records would only be automatically resolved if every record in the group links to every other record in the group and the score and subsequent category of each link is strong enough not to require clerical review. Conversely, if any of the links in a group need reviewed then the whole group would need reviewed.
In cases where there is some ambiguity about the matches, for example, where a match is identified but there is potential information to indicate they are two different respondents, it may be better to resolve the responses. Dual-System Estimation, used in coverage adjustment (https://www.scotlandscensus.gov.uk/documents/pmp001-estimation-and-adjustment-methodology/), can detect the level of missingness within a dataset, by comparing it with another independent dataset (in this case the census coverage survey). If records for distinct individuals were resolved in error in RMR, the resulting undercoverage could be corrected for in coverage adjustment. However, if records representing the same individual were not resolved in RMR, the resulting overcoverage would not be corrected for in coverage adjustment. In ambiguous cases, it would therefore be better to resolve records.
As a quality assurance step a sample of the automatically accepted links were clerically reviewed as well.
2.2 Census – Administrative Data Linking
The records in the groups to be resolved are then linked to the administrative data. For this the NHSCR (National Health Service Central Register) was used. The NHSCR is a dataset of people who were born in Scotland, or are or have been registered with a GP in Scotland.
Approval to use the NHSCR was granted by the Public Benefit and Privacy Panel for Health and Social Care (PBPP-HSC). None of the information from the NHSCR makes its way into the census dataset. It is only used to assist decisions on whether to resolve census records together.
If there are no administrative records, or only one administrative record linked to the group, then the group would be resolved as planned. However, if there were multiple administrative records, the group would be clerically reviewed alongside the administrative records.
This is an additional layer of quality assurance. If we have two census records in a group that is being considered for resolution then if there were also two matching records in the administrative dataset, this would suggest that there were in fact two distinct persons, and so the group of linked records should not be resolved to one person.
This method takes the records in the groups and links them to the administrative data source. This is done by blocking on postcode, and using the same methodology as the initial linking of census records to census records. The only difference is that there are no recorded relationships between the administrative data source records and the census records (as they are from independent datasets).
In addition there is a further search across the whole of the administrative data source, but only for cases where name and date of birth agree exactly. All such links are sent for review. This is useful if the person appears at a different location in the administrative dataset, and so would be missed when blocking on postcode.
Groups were flagged for automatic resolution when:
Every record in the group links strongly to every other record in the group, no more than one administrative data record links to the census records in the group, and one of the following three conditions is met:
1. The number of groups of records associated with a particular Individual Access Code (IAC) is equal to the number of usual residents indicated on the census form; or
2. The number of usual residents is missing on the questionnaire; or
3. The records in the group come from more than one IAC; and
• All the records link very strongly to every other record; or
• All but one of the IACs in the group were unsubmitted returns.
2.3 Changes made to the methodology during processing
- Early Quality Assurance (QA) showed that some respondents sent in two responses, giving one sex and name on one form and giving a different sex and name on the second form. Instead of marking records with different sex and name but the same date of birth as twins, these were sent to clerical review to assess if this was the same person. If the clerical reviewer decided that it was the same person, the normal prioritisation would apply where individual forms are prioritised over household forms. Scotland's Census 2022 was designed to allow someone in a household to provide answers in private, if they so wished, by requesting an individual questionnaire. People had to be aged 16 or over to complete an individual questionnaire. Some households also sent in two household forms. In this case, if the clerical reviewer decided that one of the persons in both forms was the same, the usual prioritisation for two households applied: the more complete form was prioritised over the less complete form.
- Some matches were found for links that had been rejected by looking through households that had someone linked between them. The process was therefore amended to reconsider links between linked households.
- One common type of link is where name is exactly the same between the records, but date of birth is missing on one of the records. This is common because it happens between a unsubmitted return and a submitted return for the same person. Following a review of these cases, the process was amended to automatically resolve these links in such plausible cases (such as when address was the same and one of the returns was unsubmitted).
3. Conclusion
The methodology for RMR Identify was used successfully and the use of administrative data, specifically the NHSCR, supported the quality assurance process which improve the quality of the data. The groups of records identified for resolution were quality assured against the administrative data which helped identify groups where the records should not be resolved as they represent distinct individuals. The groups that were identified to be the same person will then be resolved in the Resolve Multiple Responses: Resolving Duplicates processing step.