Scotland's Census 2022 - Name Reordering – Final Methodology
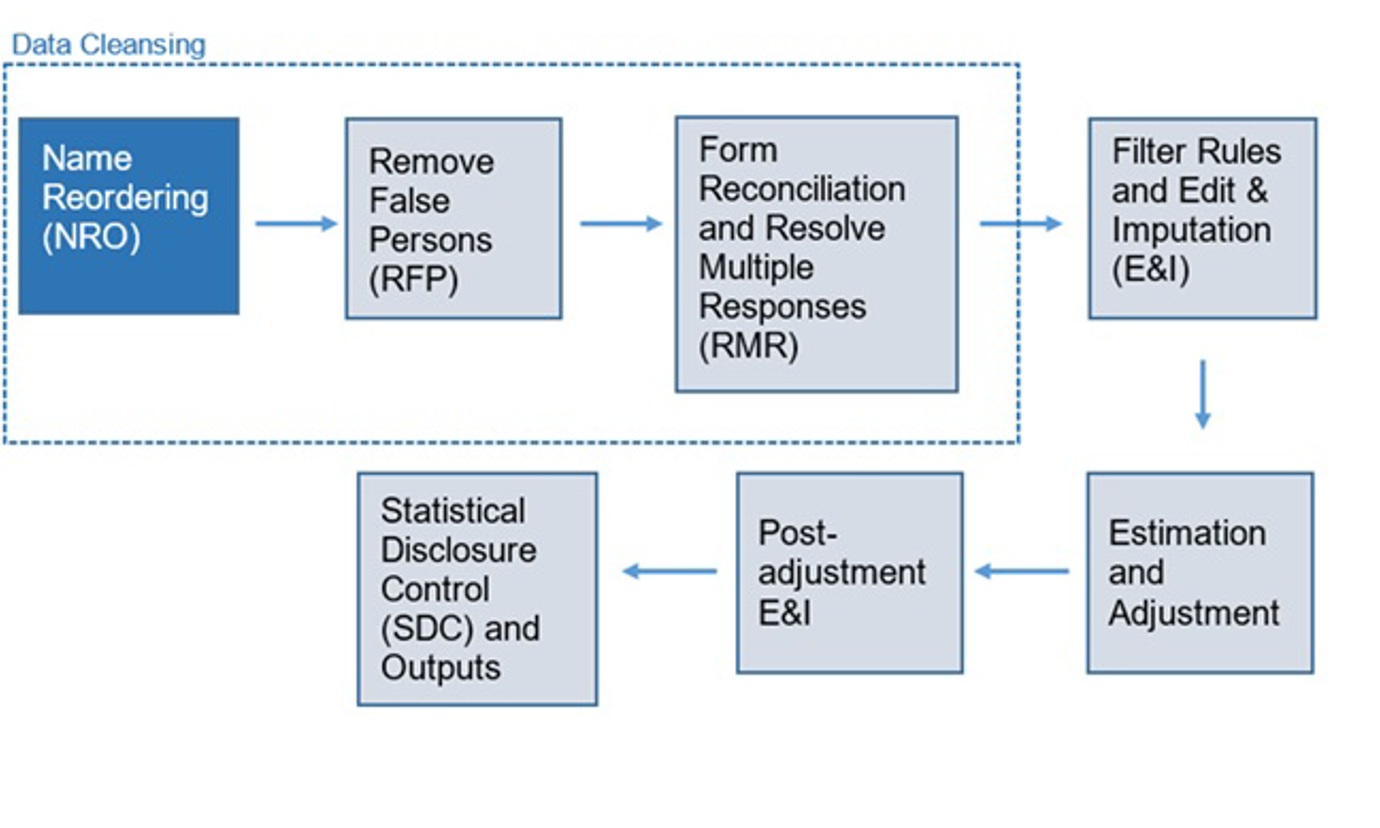
For Scotland’s Census 2022, respondents were asked to fill out their names in three different places on the paper form: the individual page, the housemember table and the relationship matrix. The guidance requested that respondents enter people in each of these fields in the same order so that person one on the relationship matrix is the same as person one on the individual forms.
However, some respondents changed the order between the different name variables, which may have led to the relationship matrix information being attached to the wrong person. Edit and imputation (E&I) may have detected this as an implausible relationship, and corrected it, but this would put extra burden on that process. Incorrect relationships that were not obviously identified as incorrect in the E&I process would have passed that process and been used in outputs.
Correcting these problems early in processing therefore had the following benefits:
- improved data quality by minimising cases where individuals are connected to the incorrect person on the household form and hence having incorrect relationship information, and
- avoiding the need for review of implausible relationships by a clerical reviewer, saving time and resource downstream in data processing.
In 2022 89 per cent of census returns were online. Online collection asked respondents to enter names once, and then these were automatically used throughout the form. This helped avoid the above problems (and any that do remain are undetectable). However, 11 per cent of responses were on paper forms and had to be checked for name ordering issues.
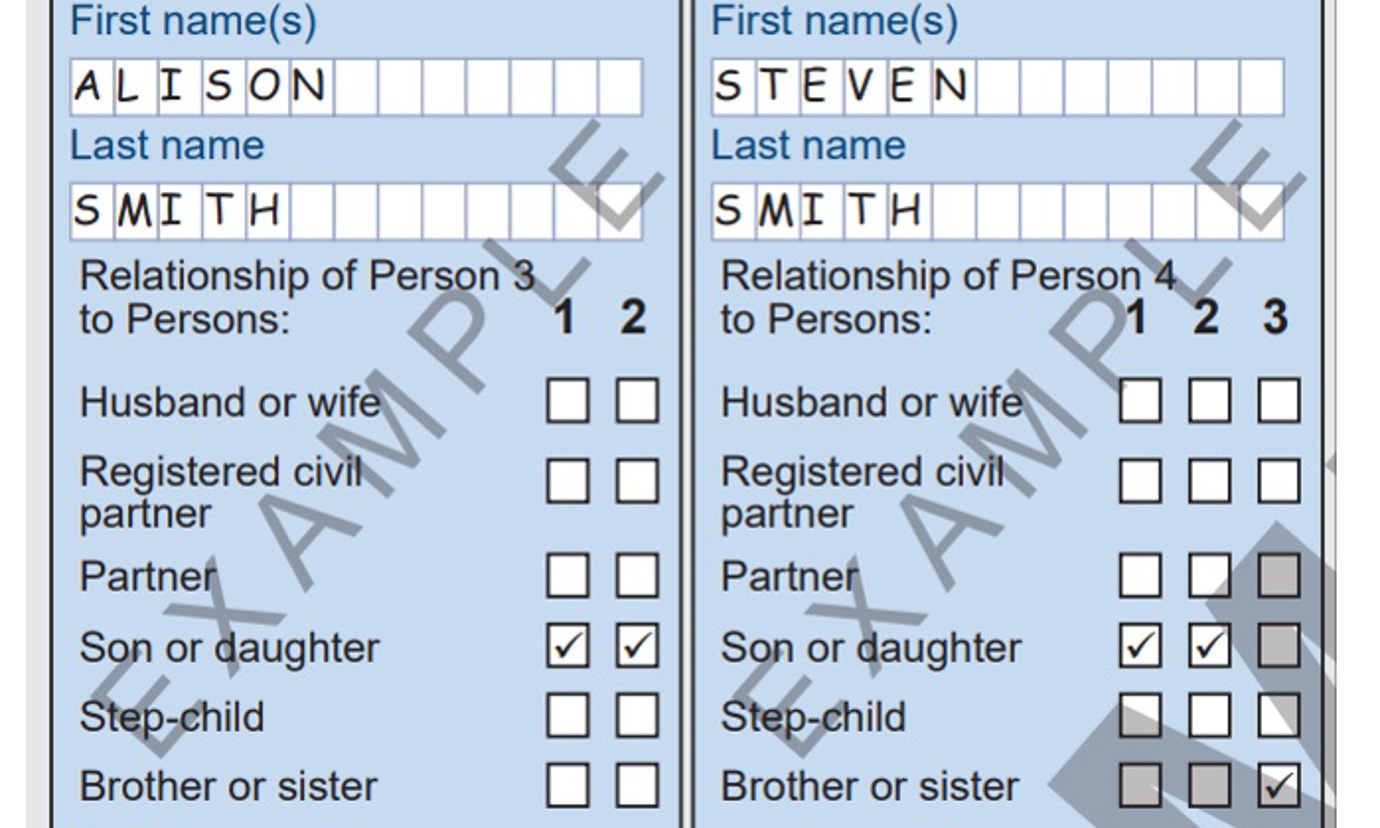
The Census 2022 paper forms captured the respondent’s name on the household form, individual form and on the relationship matrix. This allows for a direct comparison between the individuals on the relationship matrix and the individual forms. This made it possible to detect and correct any differences in ordering, ensuring that the relationship matrix information is attached to the correct persons. The relationship matrix is filled out by the respondents so that the composition of the household can be understood. The relationship matrix from the paper questionnaire can be found below:
This paper is an update to the original NRO External Methodology Assurance Panel (EMAPs) paper, which was published before data processing started. NRO was run very much as described in the EMAPs paper.
2022 Method
The 2022 Name Reordering method measured the similarity for each name on the individual forms with each name on the relationship matrix, and with those at the start of the household forms. The degree of difference between the names is recorded in a variable called cost. The optimal ordering for a household will then be the one that minimizes the total cost of the corresponding individual and household names. If there are multiple optimal orderings then we do not simply want to select one at random. Thus in such situations the algorithm would send the case for clerical review by a person.
If an optimal ordering is found that is not the default ordering (that is, household person 1 assigned to person 1 on the individual forms, person 2 to 2, and so on) then that optimal ordering is suggested. In many cases this ordering was accepted without review. However, households with the following situations were sent to review:
- The suggested ordering is not a substantial improvement on the default ordering
- There is no unique optimal ordering (generally when there are multiple people with the same name in a household
- The optimal ordering involves a link with a high cost, perhaps suggesting that something has gone awry.
- These records were handled through clerical review which meant a person examining the household and making a decision on the ordering.
At the start of live data processing, it was discovered that some respondents had transposed names. This consisted of respondents filling out the relationship matrix in a way that meant one person had two first names and the second person had two second names. These were identified and resolved before NRO was run so that they did not cause problems for later processing steps.
Conclusion
Name Reordering was run successfully and was able to correct a considerable number of orderings, covering around 0.1 per cent of records. Many of the identified cases were reordered automatically without human input; the remainder were clerically reviewed.