Scotland's Census 2022 - Edit and Imputation Final Methodology
1. Background
Edit and Imputation (E&I) is part of the fourth step of the census data processing journey as well as part of the sixth.
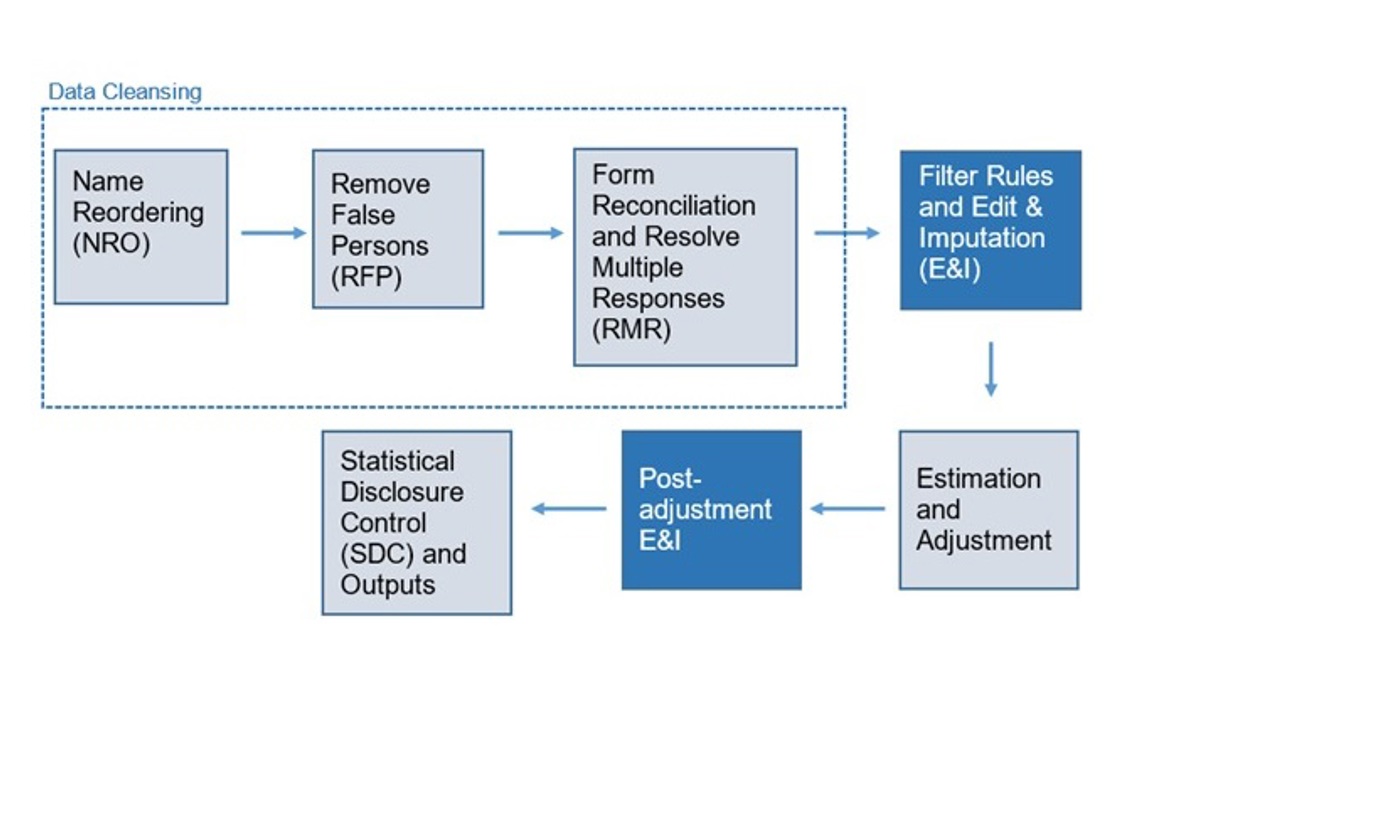
Although every effort is made to collect full and accurate census responses, inevitably some people do not complete all questions leading to incomplete returns. Census returns can also contain invalid and inconsistent responses, which were due to respondent error or procedural error such as limitations of the data capture process for paper questionnaires.
There is an expectation that the main census outputs are complete and consistent, therefore this was achieved by the Edit and Imputation process during data processing, before the production of census outputs (Figure 1). Using statistically robust methods, the dataset was imputed making the best use of all the information available. This used a process of donor imputation, where a record that requires imputation is compared to find an appropriate similar record and the values are copied across in place of the missing or inconsistent values.
The following paper is an update on the outstanding decisions after the original E&I External Methodology Assurance Panel (EMAP) paper, which was published before data processing started. More information on the detailed background and methodology of E&I can be found here.
1.1 Prevention of errors
Responses are missing if the respondent skips a mandatory question without being instructed to do so. A value may be invalid, for example, if it is out of range (e.g. 612 years old), if more than one box was ticked for a single-tick question (e.g. you cannot answer “yes” and “no” to the question on full-time education), or if the value in a text field does not yield a valid response (e.g. “pregnant” is not a health condition lasting, or expected to last, longer than 12 months). A value is inconsistent if it contradicts other information. For example, if an individual is aged 7 and is listed as a parent of another household member, the age and the relationship will both be flagged as inconsistent, and one of these values must be changed in order to resolve the inconsistency. If a value is missing, invalid or inconsistent, then the record will be marked as such and require imputation.
For Scotland’s Census 2022 respondents were encouraged to respond online and this is reflected in the 89% of people who responded doing so online. We made use of the online questionnaire technology to reduce the number of errors people made. For example, the online collection instrument reminded respondents to provide a response if they tried to skip a mandatory question without answering it, and provided opportunities to review responses. Online responses naturally did not contain some of the errors we see in paper responses, for example, scored-out questions being automatically scanned as ticks, and handwriting recognition issues which are particularly problematic for numeric fields. When answering the date of birth question online, the calculated age was displayed: this reduced the number of people accidentally giving us the current year instead of their birth year. An error message was displayed if an answer was out of bounds, for example if the date of birth entered was after census day. For this reason, the fact that the majority of respondents completed online reduced the number of issues to be resolved by E&I.
Many older people and other digitally excluded demographics preferred to respond by paper rather than online. Due to this demographic difference between online respondents and paper respondents response mode (paper or online) was taken into account during E&I processing when scoring similarity between donor records and the record requiring imputation.
2. 2022 Methodology
The process used nearest-neighbour imputation methodology through software developed by Statistics Canada called the Canadian Census Edit and Imputation System (CANCEIS). This software was used in 2011, as well as in the rest of the UK for their 2021 censuses.
2.1 Modularisation
A module can be thought of as a collection of variables which are imputed at the same time. By imputing variables at the same time rather than one after the other, we can resolve inconsistencies between variables based upon the characteristics of the entire record, rather than by which variable is imputed first. Potential imputation actions are assessed on how well they minimise the change to the record that needs to be imputed, and how plausible they are in terms of similarity between the imputed record and the donor record.
The variables are grouped together thematically so that they contain variables which are, to an extent, related to and predictive of each other. For example, a person’s perception of their general health is related to whether they have any long-term health conditions, but it is not directly related to their skills in Gaelic and Scots.
The modularisation of the variables for 2022 can be found below:
|
Demographics |
Culture |
Health |
Labour market |
|
Age Sex Marital status Full-time student Term-time location Relationships Activity last week |
Address 1 year ago Country of birth Date arrived in UK Ethnicity National identity Language questions Passports British Sign Language (BSL) |
Carer Disability Health Long-term conditions
|
Qualifications Ever worked Hours worked Employee status Supervisor Industry Occupation Work/study address Method of travel Ex-service
|
Table 5: Modularisation of non-voluntary person variables in 2022:
Where variables will be imputed
In addition to this, only Demographics and Culture were imputed as households, the remaining modules were all done on an individual basis.
For the household variables, the following were imputed in a single module: accommodation type, self-contained, bedrooms, central heating, tenure, landlord, and cars.
2.2 Processing Units
Due to computational limitations in the 2011 Census, the census data was split up into processing units. With methodological advances such as being able to impute larger households together, and improvements in processing power, the decision was made not to use processing units, and to process the entire Scotland dataset in the same batch. However, due to differences in questionnaire types and variables we processed household questionnaires separately from communal establishment questionnaires.
2.3 Partial codes
For postcode, occupation and industry questions, a response may not be complete enough and could result in a partial code. For example, occupation codes are hierarchical where each of the four digits in the code give a more precise occupation. A response of “teacher” is not precise enough to distinguish between the full codes for “primary teacher” or “secondary teacher” and so on, and so would be given the partial code that encompasses all teaching occupations. These partial codes were run through E&I to impute complete code values from the partial ones, for example where we had a partial postcode of “EH12”, imputing a full postcode within that postcode district.
2.4 Relationships
The relationships question in the questionnaire has been improved for 2022 to help respondents fill it in:
· In-question guidance added for in-laws (other relation)
· Half-siblings (sharing one parent) were now classed with siblings (two parents in common) rather than step-siblings (only step-parents in common)
· Name field on paper questionnaires was not captured in 2011. The name field on paper questionnaires was captured to help match individual questions (age, sex, marital status etc.) with relationships
· The online questionnaire was easier to fill in: it uses the format <person name> is [choose relationship] to <person name>, and relationships already filled in are displayed in the other direction for checking (if Alice is parent of Bob, then for Bob’s questions it shows that Bob is child of Alice).
Together with responses being largely online, this resulted in an increase in incoming quality of relationships, which then increased the quality of imputed relationships.
Of the three Relationship Algorithms used in 2011 detailed in the EMAP paper, only Relationship Algorithm 1 was used, to deterministically correct common errors (parent-child relationship reported the wrong way round) or missing relationships that could be determined. We imputed the first 11 people from larger households together with individuals from households of size 11. Then persons 12+ were imputed as individuals using donor imputation in CANCEIS for all other demographics variables (age, sex, student status, etc.), but the relationships could not be imputed this way. We used CANCEIS to detect and flag missing, invalid and inconsistent relationships for these remaining relationships, but decisions on how to resolve these relationships were done by manual inference using the other household relationships, and supporting information such as age and marital status.
2.5 Edit Rules
An edit rule is a rule which determines an inconsistency or outlier. A hard edit rule is something which is impossible or so rare that most occurrences are errors. These specify things which we did not allow in the dataset, for example a person under the age of 17 cannot drive to their place of work or study. A soft edit rule specifies something that is very unlikely. We wish to keep these in the dataset if people responded in this way but do not wish to create more disproportionately through imputation. An example is that a person is unlikely to be more than 65 years older than their child.
Changes to the edit rules were driven by changes to the questions, changes in society (e.g. legalisation of same-sex marriage, legalisation of opposite-sex civil partnership), and improvements to the quality of data.
We worked closely with the Office for National Statistics (ONS) and Northern Ireland Statistics and Research Agency (NISRA) to ensure harmonisation of outputs across all parts of the UK, with the use of hard edit rules being the main place in E&I where harmonisation mattered, as they determined what is not allowed within the data.
A complete list of edit rules is shown in Section 4.
2.6 Administrative Data
Administrative Data was used to enhance Edit and Imputation in 2022. The census dataset was linked to the administrative dataset and compared dates of birth. Where the census date of birth is missing or different from the administrative date of birth, an admin age was provided. This information attached to each census record provided additional information to aid the imputation process. Where the census age is missing or different from the admin age, we did not directly copy the value from the admin dataset into the census responses, but it informed selection of donor information where the census age is missing or inconsistent.
2.7 Voluntary Questions
Two new questions were included in 2022: sexual orientation and trans status or history. These questions were voluntary and only for those aged 16 and over. As with the voluntary question on religion, not stating a sexual orientation or trans status or history were valid responses. Therefore we did not generally impute a response for those who responded to the census but did not answer the questions. We did impute sexual orientation and trans status or history for those who did not respond at all to the census (synthetic records added in Estimation and Adjustment – see separate paper) so that the results for this question cover everyone aged 16 and over. 'Not stated’ was one of the values that could be imputed for these individuals. The result of imputing for those that did not respond to the census at all meant that this maintained the observed distributions proportionally as synthetic records are added to the dataset. For these two variables, a separate module was set up which included age and sex as predictors.
2.8 Audit and Metrics
Imputation and non-response rates
The imputation rate for a variable is the proportion of submitted returns where that variable has been imputed due to missing or invalid values, or inconsistencies.
Since the non-response rate does not include inconsistencies, it will be lower than the imputation rate. Both are dependent on the quality of the input data: the non-response rate is a measure of how many people did not answer, or gave an invalid response to, a question. The imputation rate includes all these for mandatory questions, as well as inconsistent responses which may be due to respondent error or misunderstanding (e.g. reporting parent-child relationship the wrong way round), or may be due to process errors (e.g. the numbers in a date of birth field on a paper return are incorrectly interpreted by the automatic software, such as mistaking a 0 for a 6).
The imputation and non-response rates for each variable have been published on the Scotland’s Census 2022 website.
Imputation flags
We have produced flags for every record, in every variable, that say whether the value was imputed or provided by the respondent. These flags will continue to be a very useful tool for processes and data quality assurance, and will be a record of what was done to the data.
Imputation flags will also be useful in some circumstances, for researchers who wish to work on record-level extracts of the census dataset without imputed values. Imputation is a process which has positive implications for Statistical Disclosure Control, as data users will be unaware of whether an individual value is observed from a return, or imputed.
3. Conclusions
Edit and Imputation was run successfully as part of Scotland’s Census 2022.
Improvements to computing power and software allowed us to make better use of the CANCEIS donor imputation software, using the power of larger datasets to enable greater use of donor imputation for larger households, in order to improve accuracy and process transparency, and ensure that a much larger proportion of the population had relationships imputed using the same method (donor imputation). The increase in online responses provided higher quality data which improved the quality of imputation.
We also made better use of hierarchical codes such as postcodes and SIC and SOC codes, and used partial information to impute full codes.
We made use of administrative data for the first time to help improve the accuracy of age imputation. Where the census age is missing or different from the admin age, admin age was used, along with other predictors, to find records of a similar age to act as donors.
We would also like to thank ONS and NISRA for their help and expertise as we benefited from their experience of their respective 2021 censuses.
4. Full list of Edit Rules
4.1 Demographics Module
Hard edit rules:
· A person aged between 6 and 15 must be a student in full-time education unless limited a lot by a health problem or disability
· Two people with at least one parent in common cannot be married/civil partners/partners with each other
· A person aged under 16 cannot be a spouse or civil partner
· A parent cannot be less than 12 years older than their child
· A person aged less than 13 cannot be a partner or step-parent
· A person with a spouse in the household cannot have a marital status other than “married” or “separated”
· A person with a civil partner in the household cannot have a marital status other than “in a civil partnership” or “separated but legally still in a civil partnership”
· A person cannot have more than two parents/step-parents
· A grandparent cannot be less than 24 years older than their grandchild
· A woman cannot be more than 66 years older than her child
· If two people share a parent, then they are (half) siblings
· If someone is a parent to one child and a step-parent to the other, then the children are (half) siblings or step-siblings
· If two people are (half) siblings, then the (step) parent of one is the (step) parent of the other, or unrelated
· If two people share a (step) sibling, then they are (step) siblings
· If two people share a (stepgrand) child, then they must be partners/spouses/civil pertners/other/unrelated
· If two people are spouses/civil partners then the child of one must be the (step) child of the other and vice versa
· If two people are partners then the child of one must be either the (step) child or unrelated to the other
· If two people share a grandparent, then they are (step) siblings or cousins (other relation)
· A person cannot have more than one spouse/partner/civil partner in the household
· At least one person in the household must be 12 years or above
Soft edit rules:
· If two people share a (step) child, then they are likely to be partners/spouses/civil partners if their marital status is single, married or in a civil partnership
· If two people share a grandchild, then they are likely to be partners/spouses/civil partners
· If two people are siblings, there is unlikely to be more than a 20-year age gap
· A person aged less than 16 is unlikely to be a partner
· A man is unlikely be more than 65 years older than his child
4.2 Culture Module
Hard edit rules:
· A person cannot arrive to live in the UK before their date of birth
· If a person’s main language is BSL then they should answer yes to the BSL question
Soft edit rules:
· If a person’s main language is English, then they are unlikely to tick “not at all” for English language skills
4.3 Health Module
No rules specified beyond Filter Rules
4.4 Labour Market Module
Hard edit rules:
· A person who responded that they were “working” last week must not have “never worked”
· A person cannot be under the age of 17 and travel to work/study by driving
· There must be consistency between a work/study address of home and the method of travel to work/study being at home